
2025年8月、Meta AIが発表した新しいビジョン基盤モデル「DINOv3」。このAIが、コンピュータビジョン、つまり「AIの眼」の分野で革命を起こそうとしています。
「なんだか難しそう…」と感じるかもしれませんが、この記事ではDINOv3の本当にすごいポイントを、専門知識がなくても理解できるように分かりやすく解説します。
この記事を読めば、なぜDINOv3が画期的なのか、そして私たちの未来にどう関わってくるのかが分かります。

DINOv3とは?一言でいうと「自ら学ぶ、超巨大なAIの眼」
DINOv3をシンプルに説明すると、人間が「これは猫」「これは車」と教えなくても、大量の画像から自力で世界の仕組みを学習するAIです。
従来の多くの画像認識AIは、人間が手作業でラベル付けした(タグ付けした)画像を大量に読み込ませて学習させていました。しかし、この方法には膨大なコストと時間がかかるという課題がありました。
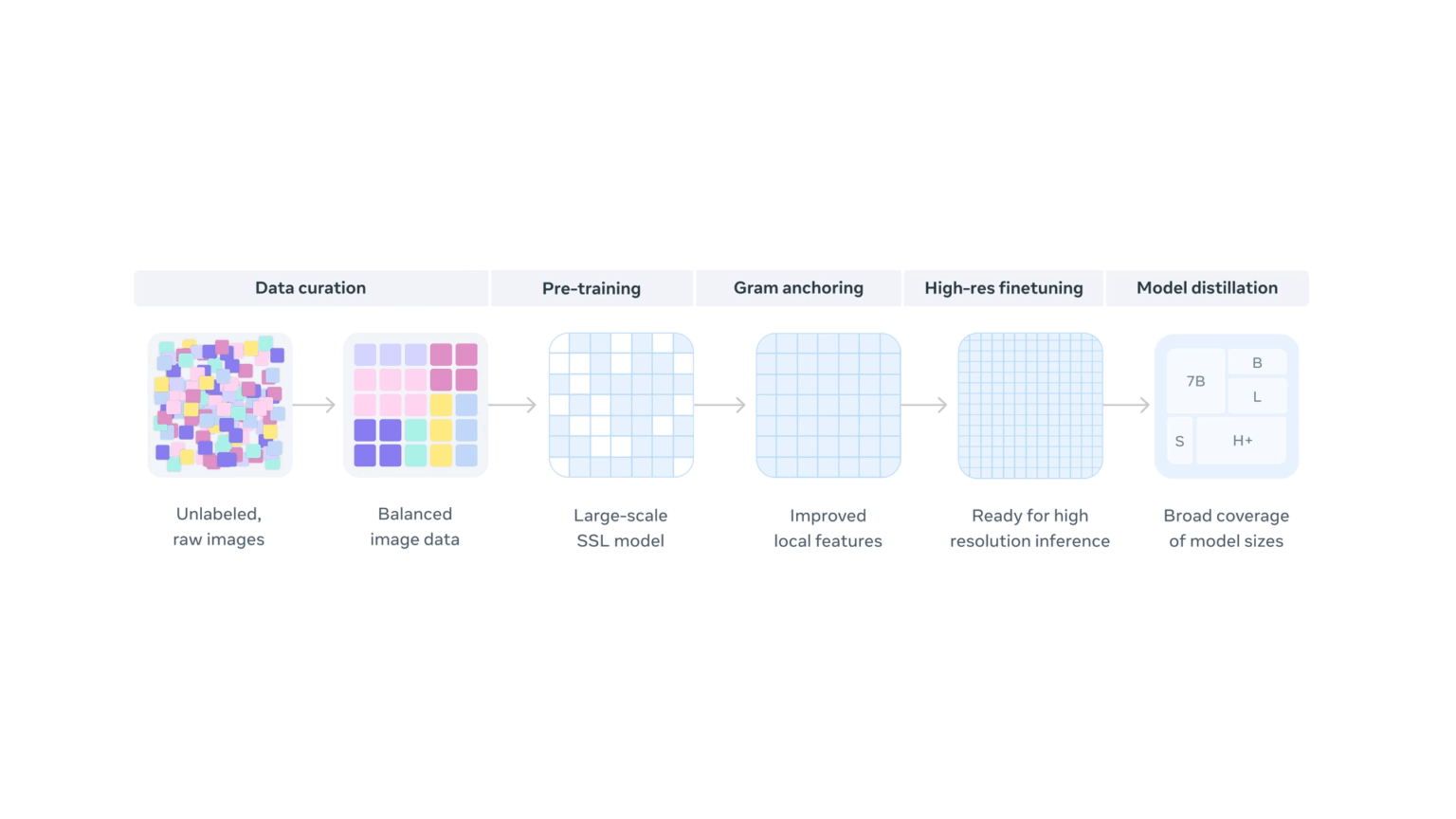
DINOv3は、ラベルのない17億枚もの画像を自ら学習する「自己教師あり学習(Self-Supervised Learning)」というアプローチを採用。これにより、従来の手法を凌駕するほどの賢さを手に入れたのです。
出典:https://ai.meta.com/dinov3/
なぜDINOv3は「革命的」なのか?3つのすごいポイント
DINOv3のすごさは、主に3つのポイントに集約されます。
1. ラベル不要の「自己学習」でコストと限界を突破
DINOv3の最大の特徴は、前述の通り「自己教師あり学習」にあります。
- コスト削減: ラベル付け作業が不要なため、開発コストと時間を劇的に削減できます。
- 未知の領域への応用: 医療画像や衛星画像など、専門家でなければラベル付けが難しい分野でもAIを活用しやすくなります。
人間による「正解」を必要としないため、AIがより多様で本質的な特徴を捉えられるようになりました。
2. 圧倒的なスケールと性能
DINOv3は、その規模も桁違いです。
- 学習データ: 17億枚(前モデルDINOv2の約12倍)
- パラメータ数: 70億(前モデルの約7倍)
この圧倒的なデータ量とモデルサイズにより、単なる物体認識(画像に何が写っているか)だけでなく、
画像の細部まで理解する「高密度予測タスク」で驚異的な性能を発揮します。
例えば、画像のピクセル単位での領域分割(セマンティックセグメンテーション)や、物体までの距離の推定といったタスクで、専門のAIモデルを超える結果を出しています。
出典:https://ai.meta.com/dinov3/
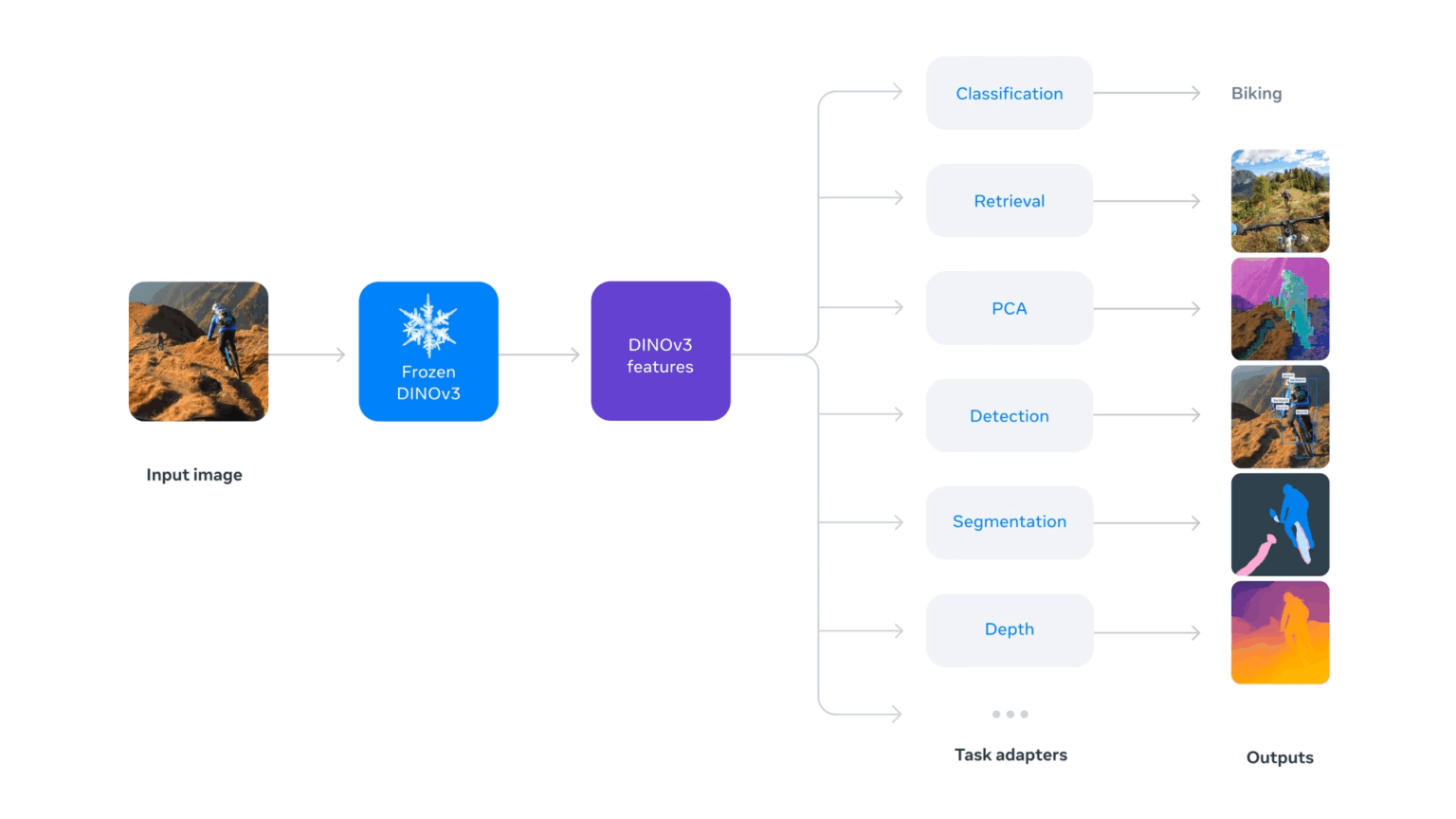
3. 「凍結バックボーン」思想で誰でも高性能AIを活用可能に
DINOv3は「凍結バックボーン」という考え方を採用しています。
これは、一度学習させた賢いAIの根幹部分(バックボーン)は固定(凍結)したまま、応用したいタスクに合わせて軽量なパーツを追加するだけで、さまざまな問題に対応できるというものです。
これにより、開発者は巨大なAIモデルをゼロから再学習させる必要がなくなり、少ない計算資源と時間で、最先端のAIの恩恵を受けられるようになります。まさに、高性能AIの民主化と言えるでしょう。
出典:https://ai.meta.com/dinov3/
DINOv3で何ができる?具体的な活用事例
すでにDINOv3は、さまざまな分野でその力を発揮し始めています。
- 環境科学(森林モニタリング)世界資源研究所(WRI)との協力で、衛星画像から樹木の高さを測定。測定誤差が従来の4.1mから1.2mへと約70%も削減され、森林再生プロジェクトの成果を正確に評価できるようになりました。
- 惑星探査(NASA)NASAのジェット推進研究所では、火星探査ローバーにDINOv2が利用されていましたが、より高性能なDINOv3は、将来の自律的な惑星探査ミッションでの活躍が期待されています。
- 医療研究(がん治療)ラベル付きデータが非常に少ないがん治療の分野で、患者の治療への反応を予測するための基盤モデルとして活用されています。
まとめ:AIの「見る力」が新たなステージへ
DINOv3は、単なる高性能なAIモデルではありません。
- ラベルという制約からAIを解放した
- 圧倒的なスケールで性能の限界を突破した
- 誰もが最先端技術を使える道を開いた
という点で、AI開発のパラダイムそのものを変える可能性を秘めています。
今後は、これまでAIの活用が難しかった専門分野や、より高度な自律性が求められるロボット工学など、さまざまな領域でDINOv3をベースにした技術が活躍していくでしょう。AIの「眼」は、私たち人間が世界をより深く理解するための、かつてないほど強力なツールになったのです。
{kind=link}